Inside VAITP: A Deep Dive into the Framework’s Techniques
The VAITP (Vulnerability Attack and Injection Tool for Python) CLI Framework is an advanced system designed to automatically inject verifiable vulnerabilities into Python code. Its purpose is to create large, realistic datasets of vulnerable code to help security researchers test and develop better defensive tools. This is achieved through a sophisticated, multi-agent architecture and a rigorous verification process.
Core Mission: To overcome the bottleneck of manually creating vulnerable code corpora by using Large Language Models (LLMs) to automate the injection of realistic and verifiable security flaws at scale.
The Dual-Agent “Planner-Coder” Architecture
At the heart of VAITP is a multi-agent system that divides the complex task of vulnerability injection between two specialized AI agents. This separation of concerns is a key design principle that allows for more controlled and precise code modification.
-
The Planner LLM: This high-level agent acts as the “brains” of the operation. It analyzes the target source code and, using one of several guidance strategies, creates a detailed plan or “meta-prompt.” The Planner selected for this role was
Llama-3.1-8B-Instructdue to its superior ability to generate high-quality, actionable instructions. - The Coder LLM: This agent is the “hands.” Its sole job is to execute the instructions provided by the Planner. It takes the original code and the prompt and performs the precise modifications needed to inject the vulnerability. The framework is designed to work with various Coder models to find the most effective combination.
Guiding LLMs with Meta-Prompting
One of the core guidance strategies tested by VAITP is meta-prompting. This technique involves using the capable Planner LLM to generate a highly optimized, task-specific prompt for the Coder LLM to follow. This effectively decomposes the complex task into two distinct stages:
- A “reasoning” stage: The Planner model analyzes the problem, the source code, and the vulnerability goal.
- A “task execution” stage: The Coder model receives a precise, structured set of commands from the Planner and executes them.
In VAITP, this took the form of the Planner creating a detailed instructional list to precisely control the Coder’s behavior.
Retrieval-Augmented Generation (RAG)
To ensure the injected vulnerabilities mirror real-world security flaws, VAITP heavily relies on Retrieval-Augmented Generation (RAG). This technique enhances the AI’s prompts with relevant, external information, preventing “hallucinations” and grounding the output in reality.
How VAITP Implements RAG:
- Knowledge Base: The system is built on a comprehensive knowledge base of over 1,200 vulnerable Python files derived from real-world Common Vulnerabilities and Exposures (CVEs).
- Semantic Search: When a task begins, the Planner queries this knowledge base to find the most semantically similar examples of the target vulnerability. This is done using a sentence transformer model (
all-MiniLM-L6-v2) and a FAISS vector index for efficient searching. - In-Context Learning: The retrieved examples are then fed directly into the prompt for the Coder LLM. This provides concrete patterns for the Coder to imitate, a strategy that proved surprisingly more effective than complex, abstract instructions.
The “Planner Bottleneck” Discovery: A key finding of our research was that for capable Coder models, a simpler strategy of direct RAG-based imitation (DIRECT_RAG) was significantly more effective than the complex meta-prompting approach. The Planner agent, while capable, could inadvertently introduce noise or ambiguity, hindering the Coder’s performance. Simpler was better.
The Multi-Stage Automated Verification Pipeline
Generating code is only half the battle. To ensure the quality and validity of the dataset, every piece of code generated by VAITP goes through a rigorous, multi-stage automated verification pipeline.
The Three Stages of Verification:
- Syntax Check: The pipeline validates that the generated code is syntactically correct Python (using AST). Any code that fails this check is immediately discarded.
- Static Analysis (SAST): Syntactically valid code is then analyzed by a suite of Static Application Security Testing (SAST) tools: DeVAIC, Bandit and Semgrep.
- LLM-based Confirmation: Finally, the raw reports from the SAST tools are aggregated and fed to another LLM agent. This “confirmation agent” acts as an automated synthesizer, weighing the evidence from all tools to make a final judgment on whether the vulnerability was successfully injected.
This automated, multi-step process allows the framework to claim that each sample in its final dataset is “statically-confirmed”, providing a high degree of confidence in the corpus’s quality and achieving a consistent 26.5% success rate at scale (with models that were not fine-tuned and are thus not “jail-broken”).
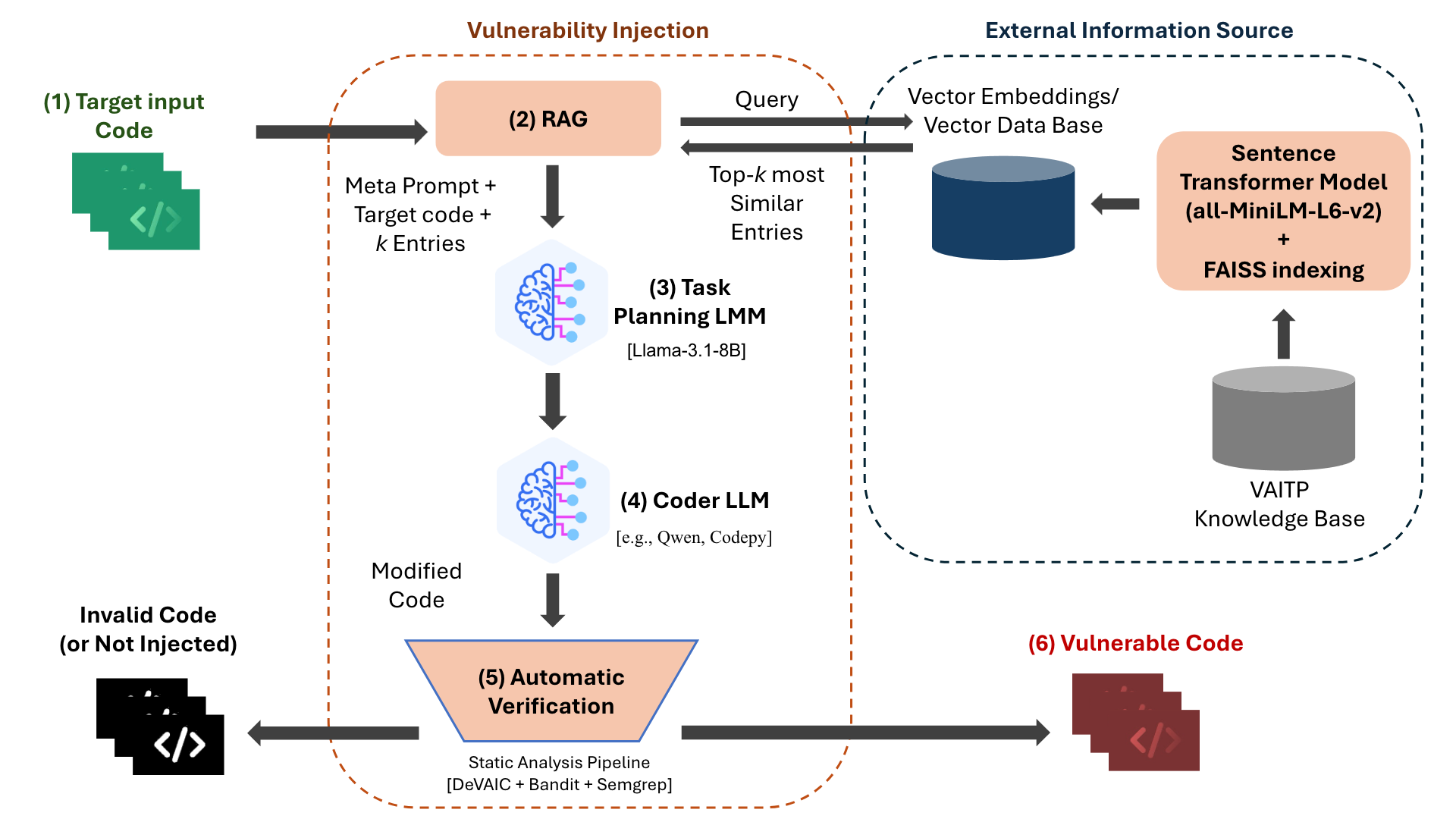
Image description
An overview of the VAITP framework pipeline, illustrating the multi-agent process from target code input (1) to the generation of statically-confirmed vulnerable code (6). The core of the architecture involves a Planner LLM that leverages RAG (2) to generate a meta-prompt (3) for a Coder LLM (4), with the final output validated by a multi-stage verification pipeline (5).